Azure IA: Aperçu
Si vous faites vos premiers pas dans l’IA et que vous souhaitez découvrir quelles sont les possibilités ou si vous avez déjà de l’expérience et souhaitez vous lancer tout de suite, alors vous êtes au bon endroit. Vous pouvez implémenter ces éléments vous-même (via un abonnement chez nous) ou nous pouvons vous assister dans leur déploiement.
IA générative

Concevez un assistant IA personnalisé à l’aide de ChatGPT. Expérimentez avec les modèles GPT-3.5-Turbo et GPT-4.

Générez des images uniques en créant des descriptions en langage naturel à l’aide du modèle Dall E.

Transcrivez votre audio avec le modèle Whisper.

Connectez et mettez à la terre vos données.
Déployez sur une application Web ou un Power Virtual Agent (Copilot Studio).
- via des flux thématiques prédéterminés déclenchés par des phrases prédéterminées
- via une IA générative basée sur un site Web (public ou SharePoint)
- via l’IA générative basée sur des documents tels que des PDF
Apprentissage automatique (Machine Learning)
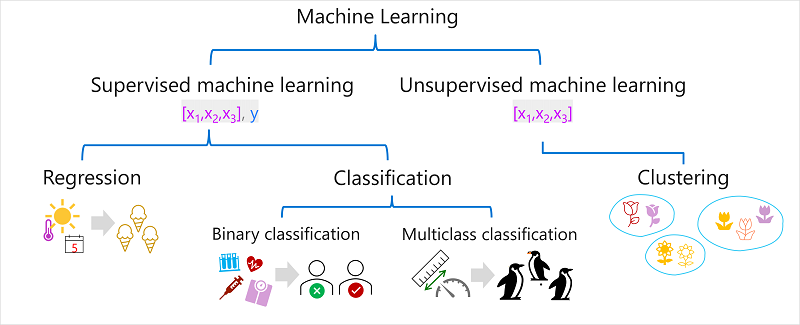
L’apprentissage automatique supervisé est utilisé pour entraîner des modèles en déterminant une relation entre les caractéristiques et les étiquettes dans les observations précédentes, afin que les étiquettes inconnues puissent être prédites pour les caractéristiques dans les cas futurs.
La régression est une forme d’apprentissage automatique supervisé dans laquelle l’étiquette prédite par le modèle est une valeur numérique. Par exemple :
- Le nombre de glaces vendues un jour donné, en fonction de la température, des précipitations et de la vitesse du vent.
- Le prix de vente d’une maison en fonction de sa taille en mètres carrés, le nombre de chambres qu’elle contient et les mesures socio-économiques de l’emplacement.
- La consommation de carburant (en km par litre) d’une voiture en fonction de sa cylindrée, de son poids, de sa largeur, de sa hauteur et de sa taille. longueur.
La classification est une forme d’apprentissage automatique supervisé dans laquelle l’étiquette représente une catégorisation ou une classe. Il existe deux scénarios de classification courants :
Dans la classification binaire, l’étiquette détermine si l’élément observé est ou non un instance d’une classe spécifique. En d’autres termes, les modèles de classification binaire prédisent l’un des deux résultats mutuellement exclusifs. Par exemple :
- Si un patient présente un risque de diabète, sur la base de données cliniques telles que le poids, l’âge, la glycémie, etc.
- Si un client d’une banque est incapable de rembourser un prêt, en fonction du revenu, des antécédents de crédit, de l’âge et d’autres facteurs.
- Si un client d’une liste de diffusion répondra positivement à une offre marketing en fonction des données démographiques et des achats antérieurs.
Dans tous ces exemples, le modèle prédit une prédiction binaire vrai/faux ou positif/négatif pour une seule classe possible.
La classification multi-classes étend la classification binaire pour prédire une étiquette qui représente l’une des nombreuses classes possibles. Par exemple :
- L’espèce de manchot (Adélie, Gentoo ou Jugulaire) en fonction de sa taille physique.
- Le genre d’un film (comédie, horreur, romance, aventure ou science-fiction) en fonction du casting, du réalisateur et du budget.
L’apprentissage automatique non supervisé implique la formation de modèles utilisant des données qui n’existent qu’à partir de valeurs de fonction sans étiquettes connues. Les algorithmes d’apprentissage automatique non supervisé déterminent les relations entre les caractéristiques des observations dans les données d’entraînement.
La forme la plus courante d’apprentissage automatique non supervisé est le clustering . Un algorithme de clustering identifie les similitudes entre les observations en fonction de leurs caractéristiques et les regroupe en groupes distincts. Par exemple :
- Regroupez les fleurs similaires en fonction de leur taille, du nombre de feuilles et du nombre de pétales.
- Identifiez des groupes de clients similaires en fonction de leurs données démographiques et de leur comportement d’achat.
- Identifiez les groupes de clients similaires en fonction de leurs données démographiques et de leur comportement d’achat.
Azure Cognitive Services: Speech
Donnez à vos applications le pouvoir d’entendre, de comprendre et même de parler à vos clients grâce à des fonctionnalités telles que la synthèse vocale et la synthèse vocale.
Azure Cognitive Services for Language
Utilisez nos fonctionnalités de traitement du langage naturel (NLP) pour analyser vos données textuelles à l’aide de modèles d’IA de pointe et préconfigurés, ou personnalisez vos propres modèles en fonction de votre scénario. Par exemple :
- Après un appel : convertissez les enregistrements des centres d’appels en texte et extrayez des informations intéressantes (telles que des informations personnelles identifiables, des sentiments)
- résumez les informations les plus importantes et les plus pertinentes.
- traduire
Azure IA Vision
Donnez à vos applications le pouvoir de lire du texte, d’analyser des images et de détecter des visages grâce à des technologies telles que la reconnaissance optique de caractères (OCR) et l’apprentissage automatique.
Document Intelligence
Vous pouvez facilement extraire des données importantes de documents ou créer vos propres modèles personnalisés sans code. Cela inclut l’extraction automatique des informations des factures et la reconnaissance des informations (nom, adresse, montant, article, etc.).
L'intégration
Beaucoup de ces éléments peuvent être utilisés en combinaison les uns avec les autres pour obtenir la solution souhaitée. N’hésitez pas à nous contacter pour obtenir des conseils.
Vous souhaitez une analyse de votre réseau ou des informations complémentaires ?
Nous pouvons vous aider avec cela.